RabbitMQ消息队列
rabbitmq可以维护很多的队列
#producer生产者import pika#建立socketconnection = pika.BlockingConnection( pika.ConnectinParameters('localhost') )#声明管道,在管道里发消息channel = connection.channel()#在管道里声明队列channel.queue_declare(queue='hello')#正式发消息channel.basic_publish(exchange='', routing_key='hello', #queue的名字 body='Hello World!') # 消息内容print("[x] Sent 'Hello World!'")connection.close() #关闭队列 #consumer消费者import pika#建立连接connection = pika.BlockingConnection(pika.ConnectionParameters( 'localhost'))#建立管道channel = connection.channel()#声明队列channel.queue_declare(queue='hello')#producer中已经声明过一个消息队列了,为什么还要声明一个?因为我们不确定哪个生产者先运行,哪个消费者先运行,如果生产者先运行,那么不写这一句也可以,但如果不写这一句并且是消费者 先运行,就会报错,为了不报错,所以两者都声明。如果声明的这个queue已经存在了,就什么也不做,直接返回。def callback(ch, method, properties, body): #ch 声明的管道对象内存地址 print('-->', ch,method,properties) print("[x] Received %r" % body)#消费消息channel.basic_consume(callback, #如果收到消息,就调用callback函数处理消息 queue='hello', #从哪个队列中收消息 no_ack=True) # 不管消息处理还是没有处理完,都不会给服务器端发确认消息print(' [*] Waiting foe message,To exit press CTRL+C')channel.start_consuming() 一个生产者对应多个消费者
RabbitMQ消息分发轮询
模拟消费者接收消息中断
#producer生产者import pikaconnection = pika.BlockingConnection( pika.ConnectinParameters('localhost') )channel = connection.channel()channel.queue_declare(queue='hello')channel.basic_publish(exchange='', routing_key='hello2', body='Hello World!') print("[x] Sent 'Hello World!'")connection.close() #consumer消费者import pikaimport timeconnection = pika.BlockingConnection(pika.ConnectionParameters( 'localhost'))channel = connection.channel()channel.queue_declare(queue='hello2')def callback(ch, method, properties, body): print('-->', ch,method,properties) time.sleep(30) print("[x] Received %r" % body)channel.basic_consume(callback, queue='hello', no_ack=True) #rabbitmq默认就会消息发送完毕就会确认print(' [*] Waiting foe message,To exit press CTRL+C')channel.start_consuming() 流程:生产者发送消息,被消费者收到,消费者处理完后,会自动给生产者发送确认,说这个消息处理完了,生产者才会把这个消息从队列中删除,
只要没有收到确认就不会删除,中间消费这个消息的消费者如果突然断掉了,生产者检测到后就会自动轮询到下一个,就代表还是一个新的消息。
D:\Program Files (x86)\rabbitmq_server-3.6.5\sbin>rabbitmqctl.bat list_queues#可以查看当前有多少个queue,并且每个queue中的消息有多少Listing queue ...hello 0hello 1#等消费者处理完后消息就会变为0
rabbitmq的持久化
#客户端,服务器端都需要写 channel.queue_declare(queue='hello',durable=True) #只持久化队列的名字,但是里面的消息还是会消失
但是在发消息端加上下面的内容就可以使消息也持久化
channel.basic_publish(exchange='', routing_key='task_queue', body=message, properties=pika.BasicProperties( delivery_mode=2, #使消息持久化 ))
如果队列的名字没有持久化,但是消息持久化了,会出现什么效果?
在消费者端如下
#consumer消费者import pikaimport timeconnection = pika.BlockingConnection(pika.ConnectionParameters( 'localhost'))channel = connection.channel()channel.queue_declare(queue='hello2')def callback(ch, method, properties, body): print('-->', ch,method,properties) time.sleep(30) print("[x] Received %r" % body)channel.basic_qos(prefetch=1) #处理完一条再发下一条 channel.basic_consume(callback, queue='hello', no_ack=True) print(' [*] Waiting foe message,To exit press CTRL+C')channel.start_consuming() 生产者发一条消息,所有的消费者都收到,这就要用到exchange,exchange是一个转发器
主要有几种类型
fanout:所有绑定到这个exchange的queue都可以接收消息
direct:通过routingKey和exchange决定哪个唯一的queue可以接受消息
topic:所有符合routingKey(此时可以使一个表达式)的routingKey所bind的queue可以接受消息
headers:通过headers来决定把消息发给哪些queue (用得少)
RabbitMQ fanout广播模式
订阅发布模型类似于收音机,开着收音机就能收到,关闭收音机就收不到消息
生产者
#因为是广播,所以不需要声明queueimport pikaimport sysconnection = pika.BlockingConnection(pika.ConnectionParameters(host='localhost'))channel = connection.channel()channel.exchange_declare(echange='logs',type='fanout)message = ' '.join(sys.argv[1:]) or "info: Hello World!" #调用命令行自己输入消息,如果没有输入,就是后面的消息channel.basic_publish(exchange='logs',routing_key='',body=message) #routing_key为空,代表queue名为空print(" [x] Sent %r" % message)connection.close() 消费者
import pikaconnection = pika.BlockingConnection(pika.ConnectionParameters(host='localhost'))channel = connection.channel()channel.exchange_declare(exchange='logs',type='fanout')result = channel.queue_declare(exclusive=True)#exclusive排他的,唯一的,不指定queue名字,rabbit会随机分配一个名字,exclusive=True会在使用此queue的消费者断开后,自动将queue删除queue_name = result.method.queue#拿到queue的名字 channel.queue_bind(exchange='logs',queue=queue_name)#绑定到转发器上,从哪个转发器上收#消费者只会从queue里接收消息,所以消费者是拿个queue去绑定exchange,而不是直接从exchange接收,这就是有queue的原因print(' [*] Waiting for logs, To exit press CTRL+C')def callback(): print(' [x] %r' % body)channel.basic_consume(callback,queue=queue_name,no_ack=True)channel.start_consuming() RabbitMQ direct广播模式
有选择的接收消息,RabbitMQ支持根据关键字发送,队列绑定关键字,发送者将数据根据关键字发送到消息exchange,exchange根据关键字判定应该讲述发送至指定队列
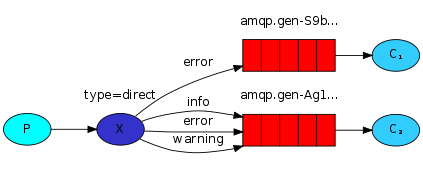
#生产者import pikaimport sysconnection = pika.BlockingConnection(pika.ConnectionParameters(host='localhost'))channel = connection.channel()channel.exchange_declare(exchange='direct_logs',type='direct')severity = sys.argv[1] if len(sys.argv) > 1 else 'info'#级别message = ' '.join(sys.argv[2:]) or 'Hello World!'#消息channel.basic_publish(exchange='direct_logs',routing_key=severity,body=message)#routing_key=severity把消息全都发到severity这个级别里print(' [X] Sent %r:%r' % (severity,message))connection.close() #消费者import pikaimport sysconnection = pika.BlockingConnection(pika.ConnectionParameters(host='localhost'))channel = connection.channel()channel.exchange_declare(exchange='direct_logs',type='direct')result = channel.queue_declare(exclusive=True)queue_name = result.method.queueseverities = sys.argv[1:]#获取执行这个脚本的所有参数,获取的是列表if not severities: sys.stderr.write('Usage: %s [info] [warning] [error]' % sys.argv[0])for severity in severities: #循环此列表绑定,每个参数都绑定到这个exchange上 channel.queue_bind(exchange='direct_logs',queue=queue_name,routing_key=severity) def callback(ch,method,properties,body): print('[x] %r:%r' % (method,routing_key,body)) channel.basic_consume(callback,queue=queue_name,no_ack=True) channel.start_consuming() RabbitMQ topic细致的消息过滤广播模式
如果要做一个更细致的区分,例如把应用程序也区分等,更细致的过滤
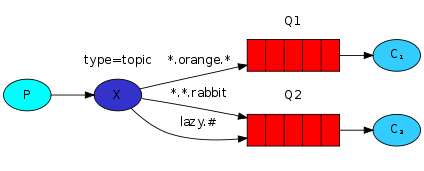
#生产者import pikaimport sysconnection = pika.BlockingConnection(pika.ConnectionParameters(host='localhost'))channel = connection.channel()channel.exchange_declare(exchange='topic_logs',type='topic')routing_key = sys.argv[1] if len(sys.argv) > 1 else 'anonymous.info'message = ' '.join(sys.argv[2:]) or 'Hello World!'channel.basic_publish(exchange='topic_logs', routing_key=routing_key, body=message)print(' [x] Sent %r:%r' % (routing_key, message)) connection.close() #消费者import pikaimport sysconnection = pika.BlockingConnection(pika.ConnectionParameters(host='localhost'))channel = connection.channel()channel.exchange_declare(exchange='topic_logs',type='topic')result = channel.queue_declare(exclusive=True)queue_name = resule.method.queuebinding_keys = sys.argv[1:]if not binding_keys: sys.stderr.write('Usage: %s [bindging_key]...\n' % sys.argv[0]) sys.exit(1)for binding_key in binding_keys: channel.queue_bind(exchange='topic_logs', queue=queue_name, routing_key=binding_key)print(' [*] Waiting for logs. To exit press CTRL+C')def callback(ch, method,properties,body): print(' [x] %r:%r' % (method,routing_key,body))channel.basic_consume(callback, queue=queue_name, no_ack=True)channel.start_consuming() RPC
目前的消息流是单向的,如果想给远程的机器发送命令,使其执行完后并返回,这种模式是rpc
#客户端import pikaimport uuidclass FibonacciRpcClient(object): def __init__(self): self.connection=pika.BlockingConnection(pika.ConnectionParameter(host='localhost')) self.channel=self.connection.channel() result=self.channel.queue_declare(exclusive=True) self.callback_queue=result.method.queue # 一个随机queue self.channel.basic_consume(self.on_response, # 只要一收到消息就调用on_response函数 no_ack=True, queue=self.callback_queue) #收self.callback_queue
def on_response(self, ch, method, props, body): if self.corr_id == props.correlation_id: # 发出去的命令就是想要的结果 self.response = body def call(self, n): self.response = None self.corr_id = str(uuid.uuid4()) # self.channel.basic_publish(exchange='', routing_key='rpc_queue', properties=pika.BasicProperties( reply_to=self.callback_queue, #让服务器端执行完命令后,把结果返回到callback_queue
correlation_id=self.corr_id, # ), body=str(n)) # 发送的消息 while self.response is None: self.connection.process_data_events() #非阻塞版的start_consuming(),有消息就接收消息,没消息就继续往下走,收到消息就会触发on_response(),on_response()把
self.response = body,所以response就不为None了,等下次while self.response is None就不成立了,也就不再接收
return int(self.response)fibonacci_rpc = FibonacciRpcClient()print(' [x] Requesting fib(30)')response = fibonacci_rpc.call(30) # 调用call方法,传参数print(' [. ] Got %r' % response) #服务器端#先接收消息,然后把执行结果返回import pikaimport timeconnection = pika.BlockingConnection(pika.ConnectionParameters(host='localhost'))channel = connection.channel()channel.queue_declare(queue='rpc_queue') #服务端要从rpc收消息,先声明一个rpc_queuedef fib(n): if n == 0: return 0 elif n == 1: retun 1 else: return fib(n-1) + fib(n-2)def on_request(ch,method,props,body): #收到消息,执行命令,然后返回结果 n = int(body) #收到的消息 print(' [. ] fib(%s)' % n) response=fib(n) # 得到fib()函数的执行结果 ch.basic_publish(exchange='', routing_key=props.reply_to, #服务器端拿到fib()函数的执行结果然后返回给客户端, properties=pika.BaiscProperties(correlation_id= \ props.correlation_id), body=str(response)) ch.basic_ack(delivery_tag=method.delivery_tag) #确保消息被消费了,任务完成,结果返回给客户端 channel.basic_consume(on_request, queue='rpc_queue') #basic_consume接收这个消息,on_request是调用on_request()函数,从rpc_queue中接收 print(' [x] Awaiting RPC requests') channel.start_consuming() Redis
单线程,通过epoll实现高并发